
O efeito DeepSeek
TechReg Insights #5

Olá, pessoal! Aqui é o Rodrigo Ferreira (após um período de silêncio na insanidade trabalho + doutorado + paternidade), e esta é a TechReg Insights.
1. DeepSeek
Nas últimas semanas, a chinesa DeepSeek virou notícia global. Vamos direto a alguns pontos importantes:
Em primeiro lugar, DeepSeek não é o nome de um modelo de IA. É, antes disso, o nome da entidade que desenvolveu esses modelos. E, se você leu os Termos de Uso ou a Política de Privacidade da DeepSeek (se você testou os serviços, é porque leu esses documentos antes, certo? 🤓Certo? 🥺), sabe que são na realidade duas organizações irmãs: Hangzhou DeepSeek Artificial Intelligence Co., Ltd. e Beijing DeepSeek Artificial Intelligence Co., Ltd.
Esse mesmo nome (DeepSeek) também é utilizado para uma série de modelos deles lançados com diferentes funcionalidades e propósitos. Assim como na OpenAI temos, dentre outras, a série “GPT” (GPT-3, GPT-3.5, GPT4o etc.), na DeepSeek temos a série… “DeepSeek” (pois é, eles não foram muito criativos) com os modelos DeepSeek LLM, DeepSeek-V3, e o que recentemente gerou bastante burburinho, o DeepSeek-R1.
Esses modelos e respectivos papers foram lançados com intervalo de poucas semanas, o que torna altamente improvável a narrativa de que era apenas um projeto paralelo da DeepSeek. Mas foram capazes de demonstrar como atingir desempenho elevado com capacidade computacional reduzida. E isso abalou os mercados.
Para quem tem interesse mais profundo, recomendo fortemente a leitura dos papers associados a cada um desses modelos. O “LLM” demonstra as técnicas de modelagem com otimização robusta de computação (paper do LLM aqui), o “V3” demonstra como implementar a arquitetura Mixture-of-Experts (MoE), algo até então mais relacionado a modelos proprietários, e com otimização computacional (paper do V3 aqui), e o “R1” demonstra técnicas de chain-of-thought (CoT), até então presentes apenas em modelos de topo proprietários, também com extrema otimização computacional (paper do R1 aqui).
Daí a reação do mercado. Se eu posso realizar treinamento com eficácia semelhante a modelos de ponta com uma fração da computação, talvez a quantidade gigantesca de GPUs da NVIDIA para os diversos novos datacenters seja desnecessária. E mais: talvez esses caríssimos modelos proprietários não sejam sustentáveis enquanto negócio - leia-se, serão incapazes de retornar o investimento -, já que soluções open source de uso barato têm atingido eficácia semelhante em poucas semanas.
Para entender melhor esse contexto, recomendo fortemente ler e estudar o texto do memo interno vazado do Google em 2023. O título do memo? "We Have No Moat, And neither does OpenAI" (em tradução literal, "Não temos fosso, e a OpenAI também não.").
Caso tenha interesse, eu fiz uma longa postagem no LinkedIn explicando os detalhes desse memo. Mas a síntese é a seguinte: (i) as big techs não possuem qualquer "molho secreto" em relação a modelos de IA; (ii) as pessoas não pagarão por um modelo restrito quando alternativas gratuitas e irrestritas forem comparáveis em qualidade; e (iii) modelos gigantes estão atrasando as big techs, porque no longo prazo os melhores modelos são aqueles que podem ser iterados rapidamente.
Pelo menos até aqui, "there is no moat" para as big techs.
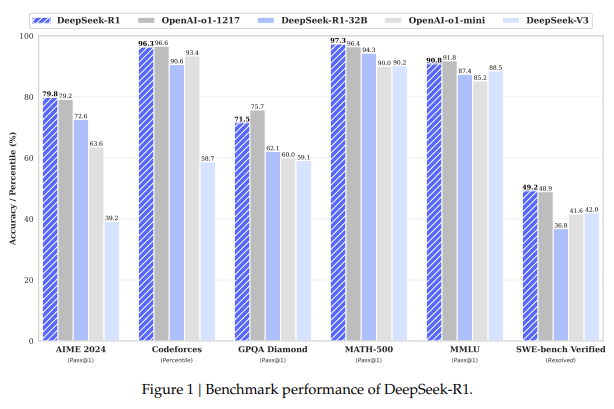
Fonte do gráfico: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.
Detalhe: os modelos da DeepSeek não são totalmente “open source”. Mas mais sobre isso na próxima edição do TechReg Insights.
2. World ID, “venda da íris” e riscos da biometria
Não tenho qualquer simpatia especial pelo Sam Altman, pela Tools for Humanity, ou pelo projeto World ID. Pelo contrário. A estrutura econômica do projeto ("tokenomics") me parece ruim, e não acho que o objetivos mais ousados do projeto devam estar nas mãos de agentes privados.
Mas a ideia de "venda de íris" porque alguém está se autenticando em um sistema mediante leitura de íris não faz qualquer sentido.
A World ID usa o Orb e o escaneamento de íris para solucionar um problema extremamente difícil em redes decentralizadas: a prova de humanidade, ou "proof of personhood".
Escrevi um longo post sobre isso e, para quem tem interesse em uma perspectiva mais técnica no tema de “proof of personhood”, o melhor artigo já escrito, no limite do meu conhecimento, é o genial “What do I think about biometric proof of personhood?”, do Vitalik Buterin, criador da Ethereum.
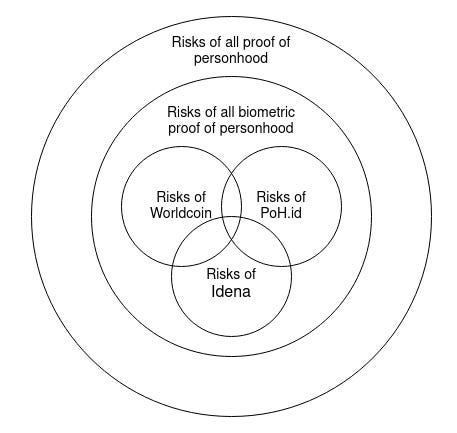
Fonte do gráfico: artigo do Vitalik supracitado.
Outro ponto super polêmico, e sobre o qual também escrevi a respeito, é se a oferta de pagamento ou vantagem contaminaria o consentimento.
Eu particularmente tenho grandes dificuldades com essa lógica. Até porque todo consentimento livre e informado deriva da percepção de vantagem no cálculo utilitário. Se você não enxerga vantagem, por que consentiria?
Não só a vantagem parece inerente a qualquer consentimento, mas a vedação do consentimento pela vantagem ao argumento de hipossuficiência do indivíduo soa uma uma abordagem autoritária e paternalista, como se o pobre, em relação a faculdade que a lei lhe confere explicitamente - é a Lei que prevê o consentimento enquanto hipótese de tratamento -, fosse incapaz de decidir por si o que prefere.
Essa abordagem paternalista é o exato oposto da autodeterminação informativa. Autodeterminação significa poder decisório nas mãos do titular de dados. Autodeterminação não é o Estado regulador decidindo pelo indivíduo, não é o controlador decidindo pelo indivíduo, é o indivíduo decidindo por si.
Precisamos buscar o equilíbrio. A dogmática traz várias hipóteses de vícios de consentimento, como a coação. Da última vez que conferi, "vantagem" não estava na lista.
E olha o paradoxo: se uma menina de 18 anos, hipossuficiente, decide se prostituir, o Estado regulador e o Direito não têm qualquer objeção. “Meu corpo, minhas regras”, ela já tem autonomia para definir sua vida e avaliar seus riscos, dane-se a hipossuficiência.
Mas, se ao invés de se prostituir, ela resolver andar até um Orb e se cadastrar por tokens dados por uma entidade privada, aí não pode. Porque, ora vejam, como o sistema exige autenticação biométrica e ela é hipossuficiente, não teria capacidade de avaliar os riscos e decidir por si. Alguma coisa muito errada não parece certa nessa lógica.
E antes que alguém levante a bandeira do “mas o vazamento de biometria pode gerar danos irreversíveis”, já adianto que está no forno um artigo desmistificando essa afirmação. Os riscos da autenticação biométrica são superestimados na bolha de proteção de dados com base no mais puro e requintado achismo.
Pensa comigo: todo santo dia alguém está monetizando dados pessoais para fraudes na dark web. O fato de haver CPF, endereço, filiação etc. sendo diariamente vendidos, mas eu nunca ter achado uma única lista vendendo dados biométricos, desses que estão por aí em abundância em prédios, condomínios e academias, é um "silêncio" extremamente "eloquente" quanto à real utilidade desses dados para fraudes, não acha? Pois é. Teremos um paper específico sobre isso na próxima RegTech Insights também.
3. IA e Copyright
O US Copyright Office publicou esta semana a segunda parte de seu relatório acerca de copyright e AI no tema “copyrightability”. A versão final do relatório - de leitura obrigatória para quem tem interesse no tema, terá três partes.
A primeira parte, que já havia sido publicada tratou de réplicas digitais, com foco nos casos de vídeos, imagens e áudios digitalmente criados ou manipulados - algo cada vez mais comum com uso de ferramentas de IA - para, de forma realística, falsamente representar uma pessoa (como um artista ou político).
A segunda parte, publicada agora, diz respeito a copyrightability, ou, mais especificamente, aos requisitos de contribuição humana necessários para que conteúdo produzido por sistemas de IA generativa possam ser objeto de copyright.
A terceira e última parte do relatório - ainda não publicada - será a mais complexa de todas (na minha opinião), e irá tratar das implicações legais do treinamento de modelos de IA com material protegido por copyright, inclusive eventuais responsabilidades. O impacto dessa terceira parte é gigantesco, seja qual for a abordagem definida. Aguardemos.
4. Papers que li (ou reli) na semana e recomendo
➡️Algorithmic regulation and the global default: Shifting norms in Internet technology (Ben Wagner) - excelente paper que discute regulação algorítmica e traz a perspectiva de regras de primeira e segunda ordem, estas últimas relacionadas às saídas dos sistemas, não aos mecanismos internos dos sistemas em si.
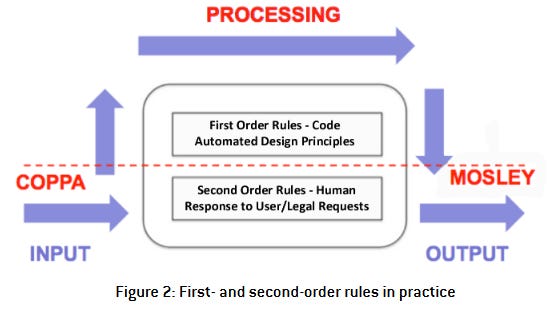
➡️What do I think about biometric proof of personhood? (Vitalik Buterin) - paper que é, no limite do meu conhecimento, o melhor já escrito acerca de proof of personhood.
Em tempo: para quem eventualmente tenha interesse na parte mais matemática de machine learning, o Prof. Laurent Younes tornou aberta a nova edição de seu livro.
5. Obrigado pelo apoio!
Todo o conteúdo da TechReg Insights e de todos os complementos é 100% gratuito, aberto e pode ser livremente compartilhado. Muito obrigado a todos os apoiadores que ajudam a manter este projeto!
Até a próxima edição!
Rodrigo